Tokens, Chinese Text, and Streaming: What Agent Builders Should Know
Why CJK prompts cost more tokens, how autoregressive generation affects tool calls, and practical budget margins for multi-step agents.
Billing, context limits, and compression triggers all speak tokens, not characters. When I build agents for Chinese-speaking teams shipping bilingual products, a few LLM mechanics prevent nasty surprises in cost and reliability.
What a token is
Models consume integers, not Unicode strings. Text is split by a tokenizer (often BPE on UTF-8 bytes) into token IDs, generated token by token, then decoded for humans.
English tends to pack efficiently—“Hello world” may be two tokens. Chinese is more fragmented for the same meaning because Han characters start as 3-byte UTF-8 sequences and BPE has less room to merge common words.
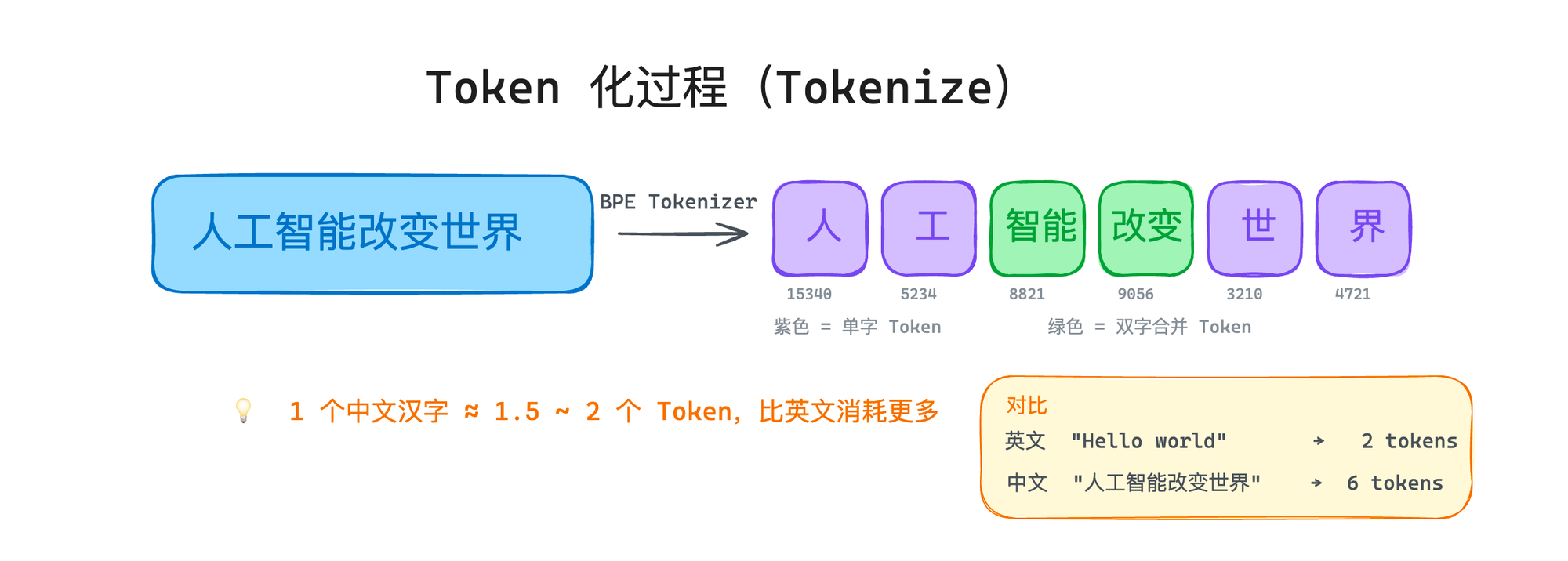
Rule of thumb I use in estimates:
- English prose: often ~1 token per word
- Chinese: roughly 1–1.5 tokens per character on major APIs (model-dependent)
- Same sentence meaning: Chinese can run ~30–60% more tokens than English
That gap is structural (byte-level BPE), not something “the next model version” magically removes.
Why agents amplify the gap
A chat message burns tokens once. An agent burns them every turn:
- System prompt + tool definitions (re-sent or cached)
- Growing transcript + tool outputs
- Planner passes in Plan-and-Execute setups
A Chinese system prompt plus verbose tool logs fills the window faster than spreadsheets predicted from English-only tests. I add a ~20% safety margin on token budgets when the primary language is CJK—same idea production tools use for underestimate risk.
This ties directly to memory and context budgeting.
Autoregressive generation (why text “types itself”)
Models do not draft a full answer in hidden memory. They emit token n, append it, predict n+1, repeat until an end marker. The typewriter UI is faithful to the algorithm.
Implications for agents:
- Streaming is natural — ship partial tokens to the UI; do not wait for completion.
- Tool JSON must be buffered —
{"name":"read_arrives in chunks; execute only after the payload parses. Production harnesses need a streaming tool executor. - Prefill can steer behavior — seed the assistant message with
{"name":"browser_to bias the next tokens toward browser tools without deleting other tool definitions from the registry.
Attention and context length (short version)
Transformer attention lets each token “look at” prior tokens. Cost grows with context size; quality can drop in the middle of long contexts (“lost in the middle”). Agent engineering is therefore about what to keep in view, not maximizing length—offload, summarize, retrieve, isolate sub-agents (six pillars).
KV cache / prompt caching (when the provider supports it) reduces cost for stable prefixes—system prompt, tool schemas—if you do not churn them every request. Changing tool lists invalidates cache; some products “mask” tools instead of removing definitions to preserve cache hits.
Practical checklist
| Question | Action |
|---|---|
| Pricing estimate | Count tokens on real Chinese prompts + tool results |
| Context ceiling | Trim/summarize early; do not rely on “200k means infinite” |
| Tool calls | Buffer streaming JSON; handle malformed spans |
| Bilingual products | Separate EN/ZH prompt assets; measure each |
| Cost alerts | Per-session token dashboards on agent workflows |
Understanding tokens is not academic—it is how I keep agent features shippable for clients who count API invoices every week.